4
簡單的問題。當我通過pytesser運行this圖像時,我得到了$+s。我該如何解決這個問題?Pytesser不準確
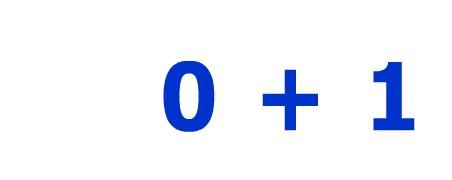{kind=link}
編輯
所以......我的代碼生成類似於上面鏈接,只是用不同的數字圖像的圖像,並且應該解決簡單的數學問題,這顯然是不可能的,如果我能得到出來的畫面是$+s
這裏是我目前使用的代碼:
from pytesser import *
time.sleep(2)
i = 0
operator = "+"
while i < 100:
time.sleep(.1);
img = ImageGrab.grab((349, 197, 349 + 452, 197 + 180))
equation = image_to_string(img)
然後我會去解析equation ...一旦一我得到pytesser工作。
小心解釋爲什麼這是被拒絕的? – Entity 2011-05-08 03:19:45
@TheAdamGaskins:是的,我可以,這個問題需要更多的信息,例如你的相關代碼是什麼,如果你可以發佈你迄今爲止想要修復的問題,那麼這將是一件好事,所以人們不會「donshing – Trufa 2011-05-08 03:22:27
抱歉,由於某種原因,我不能編輯前一個,因此,那些回答你問題的人不需要爲你完成所有繁重的工作和所有的工作,這應該是如果你添加更多的信息並且把它作爲一個完整的問題,我將刪除我的downvote – Trufa 2011-05-08 03:24:28