12
我想創建與編碼處理的一些樣本程序,具體我想 使用寬字符串等:規格在MSVC++源字符集編碼的,像GCC「-finput-字符集=字符集」
wstring a=L"grüßen";
wstring b=L"שלום עולם!";
wstring c=L"中文";
因爲這些都是示例程序。
這對於將源代碼視爲UTF-8編碼文本的gcc來說絕對是微不足道的。 但是,直接編譯在MSVC下不起作用。我知道我可以使用轉義序列將它們編碼爲 ,但我寧願將它們保留爲可讀文本。
是否有任何選項可以指定爲「cl」的命令行開關,以便 使這項工作成爲可能? 有有任何命令行開關一樣gcc'c -finput-charset
感謝,
如果沒有你怎麼會建議讓文字自然的用戶?
注意:將BOM添加到UTF-8文件不是一個選項,因爲它不會被其他編譯器編譯。
注2:我需要它在MSVC版本工作> = 9 == VS 2008
真正的答案:有編碼組合無解
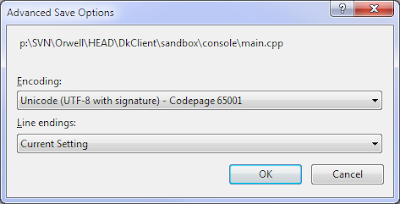
這真是令人驚訝的MSVC++沒有這樣的編譯器的選項。真是太遺憾了...... – 2011-03-13 22:37:02
我問你這個問題的意思是*源文件** charset *的規範。 *源字符集*是用於編譯器內部使用的實現定義字符集的標準中的術語。 – 2011-03-14 20:20:08
@PiotrDobrogost有人猜測爲什麼微軟沒有通過本機支持編譯和SDK的UTF-8來滿足世界其他地區的需求,並且在必須國際化Windows應用程序的程序員的生活中增加了如此多的低效率,麻煩,混亂和痛苦在UTF-8世界。但我有一個猜測;它被稱爲*官僚主義*和*利潤動機*超過關心或質量的關注。 – 2015-01-10 02:16:33