1
我一直在試圖匹配這個正則表達式無濟於事。我需要做的是做一個非貪婪的比賽將在這種情況下,最新的數字匹配到一個特定的詞:下一篇:,嘗試匹配這個正則表達式
下面是全文:
<a href="/forum/view-forum/standard-trading-shops/page/1">Prev</a>
<a href="/forum/view-forum/standard-trading-shops/page/1">1</a>
<a class="current" href="/forum/view-forum/standard-trading-shops/page/2">2</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">3</a>
<a href="/forum/view-forum/standard-trading-shops/page/4">4</a>
<span class="separator">...</span><a href="/forum/view-forum/standard-trading-shops/page/3029">3029</a>
<a href="/forum/view-forum/standard-trading-shops/page/3030">3030</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">Next</a>
我需要找到3030作爲我這個答案是這段經文中的最高數字。
我累的事情:
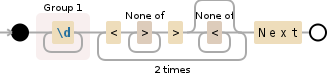
(/d)+.*?Next
然而,這總是匹配(1)一,二號線,而不是最高的3030號的第一個數字這是我的理解是.*?確實非貪婪匹配該應該匹配最新的事件。
任何人都可以幫助我嗎? 感謝 中號
你只希望它抓住3030,而不是3029的前行? – eirikdaude 2015-03-31 07:24:35