0
我在Python 3中有這個Python正則表達式代碼,我不明白。我很感激任何幫助,以解釋幾個例子的具體含義。該代碼是這樣的:Python中的波斯語正則表達式
# encoding=utf-8
import re
newline = re.sub(r'\s+(((زا(ی)?)?|ام?|ات|اش|ای?(د)?|ایم?|اند?)[\.\!\?\،]*)', r'\1 ', newline)
我在Python 3中有這個Python正則表達式代碼,我不明白。我很感激任何幫助,以解釋幾個例子的具體含義。該代碼是這樣的:Python中的波斯語正則表達式
# encoding=utf-8
import re
newline = re.sub(r'\s+(((زا(ی)?)?|ام?|ات|اش|ای?(د)?|ایم?|اند?)[\.\!\?\،]*)', r'\1 ', newline)
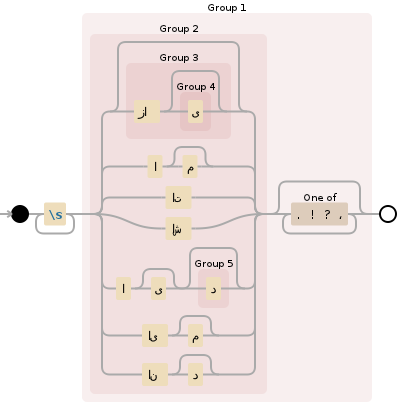
這裏是你的正則表達式:
\s+(((زا(ی)?)?|ام?|ات|اش|ای?(د)?|ایم?|اند?)[\.\!\?\،]*)
這裏是一個可視化:
你更換r'\1 '這MEA ns替換您在第一組中找到的內容,然後是空格。我不讀波斯語,但這裏是另一個例子:
\s+((a|b)[./?]*)
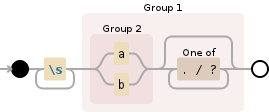
讓我們執行一些代碼:
>>> newline = ' a? b? a.'
>>> re.sub('\s+((a|b)[./?]*)', r'\1 ', newline)
'a? b? a. '
這吃之前特定多餘的空格字符組(前導\s+)並將其更改爲標識的group 1由一個空格編輯(r'\1 ')。
感謝您的回答。根據上圖,是不是第一組第一組?然後你所說的變得混亂。你能再詳述一下嗎?例如,如果我有:'newline ='رفتهاند'',運行代碼後應該得到什麼? – TJ1
提供你的'newline'是unicode,你會得到同樣的結果,因爲沒有多餘的空格。 'r'\ 1''將保留組1中除空格以外的所有內容。 – dnozay
非常感謝您提供非常有用的示例。 – TJ1