0
我正在處理加載文件,並試圖編寫一個正則表達式來檢查文件中沒有正確數量的分隔符的任何行。讓我們假裝分隔符是%(我不確定此文本字段是否支持加載文件中的分隔符)。我寫的正則表達式的發現是正確的爲所有行:正則表達式排除重複值
^%([^%]*%){20}$
有時是更有益地發現,沒有分隔符的正確數量的任何行,所以要實現這個目標,我寫了這個:
(^%([^%]*%){0,19}$)|(^%([^%]*%){21,}$)
我很關心這個(以及我寫的任何正則表達式的效率),所以我想知道是否有更好的方法來編寫它,或者如果我寫它的方式是好的。我想也許會有一些方法來使用與重複令牌交替使用,例如:
{0,19}|{21,}
但這似乎並不奏效。
如果知道這一點很有幫助,我只是通過Sublime Text中的文件進行搜索,我相信它使用PCRE。儘管我發現即使在格外大的加載文件中也能很好地工作,我也樂於提出使第一個正則表達式更好的建議。
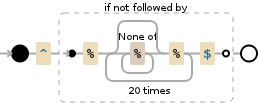
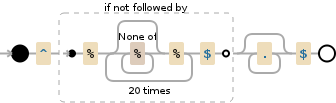
哇,我真不敢相信我根本就沒想到消極前瞻的。謝謝! – mikev