0
我有一個很難得到這個..正則表達式的表的innerHTML來發現特殊charcters
我有這樣的HTML代碼:
<table border='1'><tr><th></th><th>Fact Questions Report Type Count</th></tr><tr>
<td class=' sorting_1'>0 - 18</td><td>78</td></tr><tr><td class=' sorting_1'>19-64</td>
<td>78</td></tr><tr><td class=' sorting_1'>65+</td><td>78</td></tr><tr>
<td class=' sorting_1'>אין גיל</td><td>78</td></tr><tr><td class=' sorting_1'>נפטר</td>
<td>78</td></tr><tr><td class=' sorting_1'>Unknown</td><td>78</td></tr></table>
正如你看到的有特殊字符我想趕上像:
אין גיל,נפטר
我認爲做一個正則表達式,這將排除所有的話\W一第二號\D和those->=|'
但我不能得到它的工作..
的完美解決方案將獲得兩個項目進行專項charcters ... אין גיל,נפטר
PS:可能有其他特殊charcters
我會喜歡看到這個在這裏一個例子:RegexPal - Online Editor
TNX!
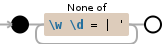
這可能嚴重依賴於您使用的正則表達式引擎。 PHP? C#? Java的? –