是,檢查點是阻塞操作,使得其它的活動期間停止處理。通過這種狀態序列化來停止計算的時間長短取決於您正在寫入的介質的寫入性能(您是否聽說過Tachyon/Alluxio?)。
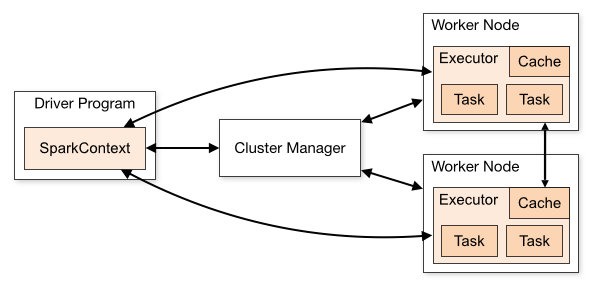
在另一方面,先前檢查點數據不被讀取每一個新的檢查點操作:將狀態信息已經被保存在作爲流被操作星火的緩存(檢查站只是進行備份它)。讓我們想象一下最簡單的狀態,即所有整數的總和,它們在整數流中相遇:在每批中,根據批次中看到的數據計算該總和的新值 - 並且可以存儲該部分和在緩存中(見上)。每五個批次左右(取決於您的檢查點間隔),您將該總和寫入磁盤。現在,如果您在後續批次中丟失了一個執行程序(一個分區),則只需重新處理該執行程序的分區(最多五個分區),即可重新構建總計(通過讀取磁盤以查找最後一個檢查點,並重新處理最後5個批次的缺失部分)。但在正常處理中(無事件),您無需訪問磁盤。
由於您必須修復您願意從中恢復的最大數據量,因此我沒有通用公式。舊的文檔給出a rule of thumb。
但在流式傳輸的情況下,您可以將您的批處理間隔想象爲計算預算。假設您的批處理間隔爲30秒。在每批中,您需要30秒來分配寫入磁盤或計算(批處理時間)。爲確保您的工作穩定,您必須確保批處理時間不超過預算,否則將填滿羣集的內存(如果需要35秒來處理並「刷新」30秒的數據,在每個批次中,您都會採集比您在同一時間刷新的數據更多的數據 - 因爲您的記憶是有限的,這最終會導致溢出)。
假設您的平均批處理時間爲25秒。因此,在每個批次中,您的預算中有5秒的未分配時間。您可以將其用於檢查點。現在考慮檢查點的使用時間(您可以從Spark UI中調出)。 10秒? 30秒 ?等一下 ?
如果它需要你c秒檢查點上bi秒批次間隔,用bp秒批處理時間,你會從檢查點(加工過程中沒有處理這個時候,仍然來自於數據)「恢復」 :
ceil(c/(bi - bp))批次。
如果它需要你k批次從檢查點「恢復」(即恢復從檢查點引起的遲到),並且您正在檢查點每p批,你需要確保你實施k < p,避免不穩定的工作。因此,在我們的例子:
注意,這裏假設你的檢查點的時間是恆定的,或者至少可以通過最大恆定爲界。可悲的是,這往往並非如此:一個常見的錯誤是忘記使用操作,如updateStatebyKey或mapWithState刪除狀態的一部分,狀態流 - 但國家的大小應始終爲界。需要注意的是多租戶集羣上所花費的時間寫入磁盤並不總是一個常數 - 其他工作可能試圖同時訪問磁盤上的同一個執行者,從磁盤IOPS餓死你(在this talk了Cloudera的IO吞吐後顯着降低報告> 5個併發寫入線程)。
注意你應該設置檢查點間隔,因爲默認是發生超過default checkpoint interval首批 - 即10S - 最後一批了。對於30秒批處理間隔的示例,這意味着您每隔一批處理一次檢查點。對於純粹的容錯原因(如果重新處理幾個批次沒有那麼大的成本),通常太頻繁了,即使按照您的計算預算允許,並導致以下種類的性能圖中的尖峯:
