您的表情與第一個點匹配,並且.*?也會匹配點。因此,您可以獲得Shyam and you...作爲匹配。嘗試更改(.*?are.*?)至([^\\.]*?are[^\\.]*?)以匹配除點之外的所有字符。
請注意,您還可以將表達式簡化爲\s*([^\.]*are[^\.]*)(此處爲非Java符號)。這會有相同的結果,但也會匹配"You are Shyam. You are Mike."。
該表達式可以匹配不包含點的字符序列與中間的「are」之間的任意空格。請注意,這也將單獨匹配are,因此您可能需要將[^\.]*更改爲[^\.]+。
編輯:
爲了考慮您的更新例如,你可以試試這個表達式(休息下來如下):
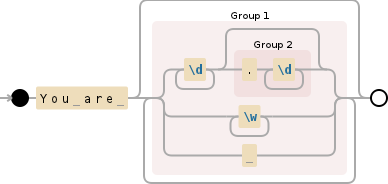
\s*((?:[^\.]|(?:\w+\.)+\w)*are.*?)(?:\.\s|\.$)
輸入:I am here. You are almost 2.3 km away from home. You are Mike. You are 2. 2.3 percent of them are 2.3 percent of all. Sections 2.3.a to 2.3.c are 3 sections. This is garbage.
輸出:You are almost 2.3 km away from home ,You are Mike,You are 2,2.3 percent of them are 2.3 percent of all,Sections 2.3.a to 2.3.c are 3 sections
一些注意事項:這將需要每個句子以一個圓點結尾(這可以通過用[.!?]\s|[.!?]$替換\.\s|\.$來更改),每個分隔點後跟一個空格或輸入的結尾,並且不匹配You are J. J. Abrams或2.a
請注意,在這種情況下,計算機確實很難確定句子結尾,特別是使用「簡單」正則表達式。
表達分解:
\s*前導空白不會是組的一部分,否則這是沒有必要((?:[^\.]|(?:\w+\.)+\w)*are.*?)捕獲的組,之前和之後包含are和附加的文本
(?:[^\.]|(?:\w+\.)+\w)一個非捕獲組匹配任何非點字符序列([^\.])或(|)a字序列字符(\w作爲[a-zA-Z0-9_]單點之間(快捷方式)(?:\w+\.)+\w),也非捕獲).*?字符但具有懶惰改性劑的任何序列匹配最短的序列,而不是最長(沒有它,下一個部分將沒有多大意義)
(?:\.\s|\.$)必須遵循所捕獲的基團的非捕獲組,它必須或者在輸入的結束相匹配的點,接着空格(\.\s)或(|)的點(\.$)
編輯2:
這裏的無(A|B)*基團的不徹底的測試版本:
\s*([^.]*(?:(?:\w+\.)+\w+[^.]*)*are.*?)(?:[.!?]\s|[.!?]$)
基本上(?:[^\.]|(?:\w+\.)+\w)*已被替換爲[^.]*(?:(?:\w+\.)+\w+[^.]*)*,意思是「非點的字符的任何序列,隨後通過任意數量的由點字圍繞的點組成的序列,然後是任何非點字符序列「。 ;)
參見:http://stackoverflow.com/questions/1232220/how-to-non-greedy-multiple-lookbehind-matches –
是否有一個原因,'你已經有2.3公里home.'發生輸入兩次,只輸出一次? – Thomas
提示:'^'和'$'允許您捕獲字符串的開頭和結尾 –