0
爲了下面的例子我寫了用戶,俱樂部和追隨者集合。 我想從「用戶」集合中找到「A famous club」之後的所有用戶文檔。 我如何找到這些?哪種方式最快?關於 'what do I want to do - Edge collections'查詢MongoDB(使用邊緣集合 - 最有效的方法?)
{kind=link}
更多信息
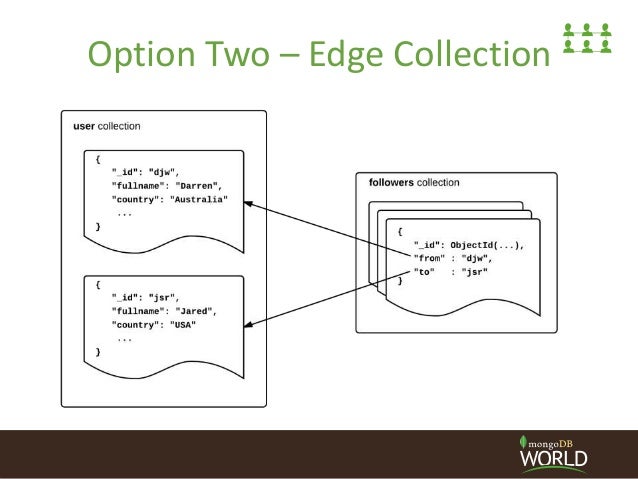
用戶收集
{
"_id": "1",
"fullname": "Jared",
"country": "USA"
}
俱樂部收集
{
"_id": "12",
"name": "A famous club"
}
關注集合
{
"_id": "159",
"user_id": "1",
"club_id": "12"
}
PS:我可以像下面的方式使用Mongoose來獲取文檔。但是,創建followers陣列需要約8秒150.000條記錄。第二個find查詢 - 使用追隨者數組查詢 - 需要大約40秒。這是正常的嗎?
Clubs.find(
{ club_id: "12" },
'-_id user_id', // select only one field to better perf.
function(err, docs){
var followers = [];
docs.forEach(function(item){
followers.push(item.user_id)
})
Users.find(
{ _id:{ $in: followers } },
function(error, users) {
console.log(users) // RESULTS
})
})
我沒有看到這個問題......你問:「我怎麼能找到它」,但你自己提供的解決方案。你的目標是什麼?爲什麼你甚至需要*一個特定俱樂部的所有追隨者的所有數據?顯示這些結果可能沒有意義?!沒有更多的上下文,沒有什麼可以添加到您的問題... – mnemosyn 2015-02-09 17:06:13
你好@mnemosyn,你是對的。我編輯了這個問題。我需要最有效的方法。如果在數百萬條記錄上工作。感謝您的關注。 – efkan 2015-02-09 17:27:38
爲什麼你一次只需要RAM中的所有數據?無論如何,你必須找出延遲來自哪裏。請記住,默認批量大小僅爲1,000,因此此代碼至少需要450次數據庫往返行程,以及實際的數據傳輸。我不知道貓鼬的開銷是多少,但分析它可能會有所幫助。另外,數組大於10,000個元素的'$ in'可能會很慢。如果您幾乎需要所有數據,那麼將所有數據首先加載到RAM中可能會更快嗎?或者整個數據集大得多? – mnemosyn 2015-02-09 18:39:57