2
我在重寫規則時將解析樹轉換爲antlr中的AST樹時遇到了麻煩。AST重寫規則,在antlr中帶「* +」
這裏是我的ANTLR代碼:
grammar MyGrammar;
options {
output= AST;
ASTLabelType=CommonTree;
backtrack = true;
}
tokens {
NP;
NOUN;
ADJ;
}
//NOUN PHRASE
np : ((adj)* n+ (adj)* -> ^(ADJ adj)* ^(NOUN n)+ ^(ADJ adj)*)
;
adj : 'adj1'|'adj2';
n : 'noun1';
當我輸入 「ADJ1名1 ADJ2」 解析樹像這樣的結果:
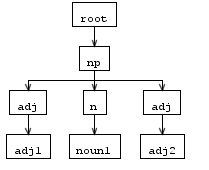
但AST樹在重寫規則看起來不完全像分析樹之後,adj是雙倍的,而不是像這樣:
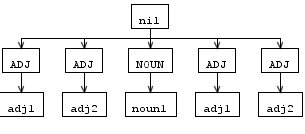
所以我的問題是我怎麼能重寫規則有一個像上面的解析樹的結果?
它的工作,非常感謝你:) –
我喜歡你的帽子。 –
@TrungL我很高興能幫上忙。 :) – user1201210