0
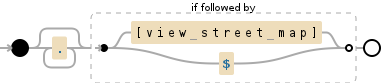
我的正則表達式的代碼如下:正則表達式週期減去最後一個字符匹配一切
(.(?!\[view street map\]))+
這是爲了匹配的一切,直到[查看街道地圖。
但是,如果我在下面
Test of the system[view street map]
使用這個表達式代碼它下面的匹配,並切斷了最後一個字符
Test of the syste
任何人有爲什麼發生這種情況的任何想法?
在此先感謝!
感謝您的解釋,是有道理的。 :) – DanielRHarris 2014-10-08 06:16:00
爲什麼你的正則表達式在這裏失敗http://regex101.com/r/hQ1rP0/54v? – 2014-10-08 06:18:49
但是,在字符串'[查看街道地圖]'上,現在會匹配'查看街道地圖]'。 – 2014-10-08 06:21:15