0
目標:返回分組匹配所有開始序列但排除大小序列。Python - 正則表達式 - 匹配所有開始序列排除其他模式
## List of strings and desired result
strs = [
'151002 - Some name', ## ('151002 - ', 'Some name')
'Another name here', ## ('', 'Another name here')
'13-10-07_300x250_NoName', ## ('13-10-07_', '300x250_NoName')
'728x90 - nice name' ## ('', '728x90 - nice name')
]
嘗試模式
## This pattern is close
##
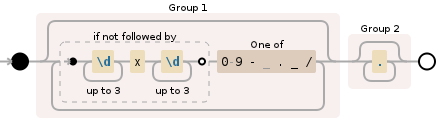
pat = '''
^ ## From start of string
( ## Group 1
[0-9\- ._/]* ## Any number or divider
(?! ## Negative Lookahead
(?:\b|[\- ._/\|]) ## Beginning of word or divider
\d{1,3} ## Size start
(?:x|X) ## big or small 'x'
\d{1,3} ## Size end
)
)
( ## Group 2
.* ## Everthing else
)
'''
## Matching
[re.compile(pat, re.VERBOSE).match(s).groups() for s in strs]
嘗試的模式結果
[
('151002 - ', 'Some name'), ## Good
('', 'Another name here'), ## Good
('13-10-07_300', 'x250_NoName'), ## Error
('728', 'x90 - nice name') ## Error
]
哇! @ r-nar多麼神奇的工具!非常感謝你的分享!我仍然沒有得到如何使用前瞻性的例子和工具讓我更接近。 **:)**看起來像我在網上遇到的每個示例都使用lookahead作爲**不包含**(因此在我的示例中,如果任何字符串具有大小 - 即300x250),則該模式將失敗)。所以當然遵循並修改它們的邏輯,我把前瞻視爲**期望的**模式的前面。你有什麼好的前瞻參考? – propjk007
我真的沒有很好的參考,但如果有幫助,可以將前瞻/後視報表視爲探針。每當正則表達式到達一個時,它將保持它的當前位置,同時使用'另一個'標記在字符串之前或之後,並匹配先行語句中的任何內容。 –
也,我使用rexegg.com我的任何正則表達式的問題,它是一個很好的概述正則表達式和技巧的網站,並提示如何使用它 –