3
我有一個132 x 107的數據集,它由2個病人類型(病人1的33個)和(99個病人2)組成。從PCA和QQ地塊中識別和刪除異常值
我在尋找離羣所以我已經運行1號4種成分的數據集和done qqplots PCA,使用以下命令
pca = prcomp(data, scale. = TRUE)
plot(pca$x, pch = 20, col = c(rep("red", 33), rep("blue", 99)))
當我使用第二部分的qqplot:
qqPlot(pca$x[,2],pch = 20, col = c(rep("red", 33), rep("blue", 99)))
下圖顯示了2個清除異常值 - 左下角的紅色點是病人1。
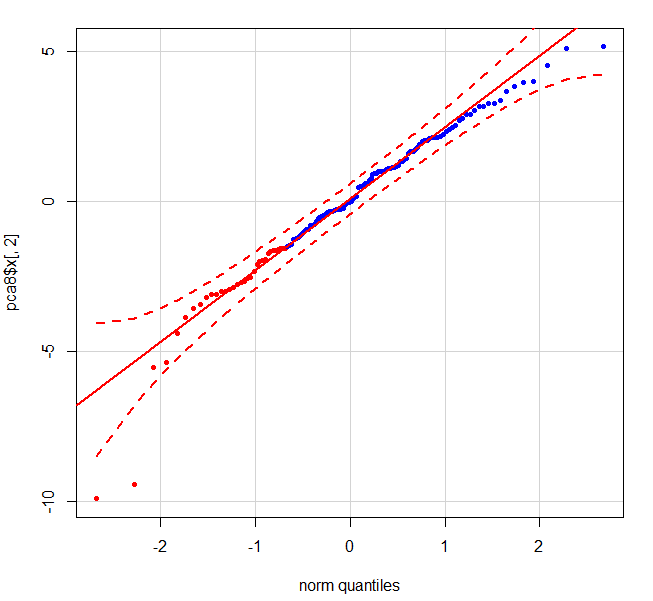
有這樣他們就可以被移除工作了數據,這些點的指數的任何直接的方式?
如果您提供[最小,可重現的示例],您更可能收到有用的答案(http://stackoverflow.com/questions/5963269/how-to-make-a-great-r-reproducible-例如/ 5963610#5963610)以及您嘗試過的代碼。謝謝! – Henrik