說明
^(?:https?:\/\/)?[^\/]+\/|([^?\n]+)
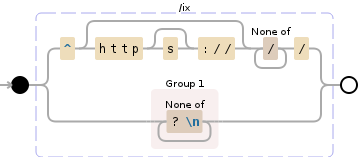
這個正則表達式將執行以下操作:
- 匹配字符串開始
http://或https://
- 跳過域名
- 捕捉的子域名之後和查詢字符串之前
例
現場演示
https://regex101.com/r/zC4gZ6/1
示例文本
youtube.com/data/beta
http://youtube.com/data/beta?Droid=This_is_not_the_droid_you_are_looking_for
樣品匹配
[1][0] = youtube.com/data/beta
[1][1] = data/beta
[2][0] = http://youtube.com/data/beta
[2][1] = data/beta
說明
NODE EXPLANATION
----------------------------------------------------------------------
^ the beginning of a "line"
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
http 'http'
----------------------------------------------------------------------
s? 's' (optional (matching the most amount
possible))
----------------------------------------------------------------------
: ':'
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
[^\/]+ any character except: '\/' (1 or more
times (matching the most amount possible))
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^?\n]+ any character except: '?', '\n'
(newline) (1 or more times (matching the
most amount possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
加分
要包括查詢字符串,如果他們存在,那麼添加(?:\?(.*?))?$ 上述表達式的末尾,以便它看起來像這樣。
^(?:https?:\/\/)?[^\/]+\/([^?\n]+)(?:\?(.*?))?$

感謝滾裝喲,你真棒。但我只有一個問題,我怎樣才能將查詢字符串也包含在結果中? –
我剛在我的答案的末尾提供了一個更新來覆蓋查詢字符串部分。這允許查詢字符串部分存在或不存在。 –