Foreward
在它看起來像你試圖解析HTML代碼與常規的表面表達。我覺得有必要指出,由於可能會出現所有可能的模糊邊緣情況,因此使用正則表達式來解析HTML是不可取的,但似乎您對HTML有一些控制權,因此您應該能夠避免使用許多正則表達式警察哭了。
說明
<\w+\s(?=(?:[^>=]|='[^']*'|="[^"]*"|=[^'"][^\s>]*)*?\[(?<DesiredValue>[^\]]*)\])
|
<\w+\s?(?:[^>=]|='[^']*'|="[^"]*"|=[^'"][^\s>]*)*>
(?:(?!<\/div>)(?!\[).)*\[(?<DesiredValue>[^\]]*)\]
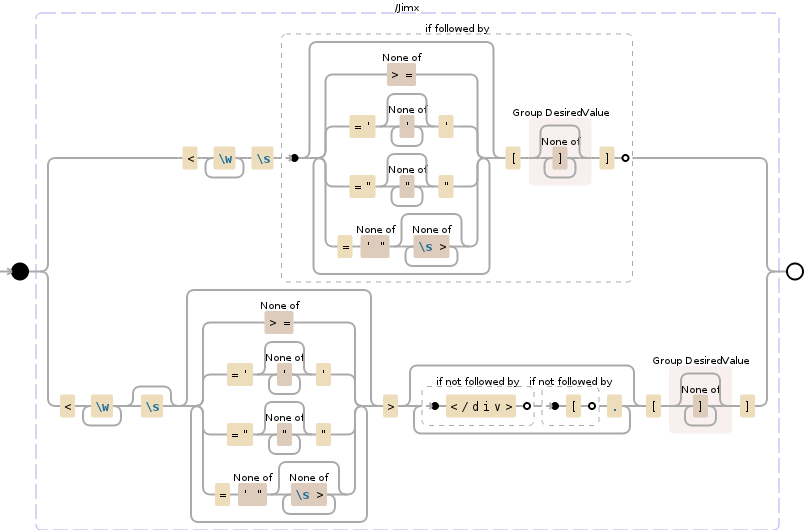
這個正則表達式將執行以下操作:方括號[some value]
- 是
[value]內
- 捕獲子是在一個標籤
- 是
[value]是不是一個標籤
- 提供子串的屬性區域內沒有嵌套在另一個值的ttributes
<input attrib=" [value] ">
- 捕獲的子串將不包括包裹方括號
- 允許任何標籤名,或與所需的標籤名稱
- 允許
value是任何字符串替換\w
- 難以避免邊緣情況
注:這個表達式最好用下列標誌使用:
- 全球
- 點匹配新行
- 忽略表達空白
- 允許重複的命名捕獲組
個
例子
現場演示
https://regex101.com/r/tT0bN5/1
示例文字
<div [value 1] ></div>
<div>[value 2]</div>
but not find a match in this example
<div attr="attribute[value 3]"/>
<img [value 4]>
<a href="http://[value 5]">[value 6]</a>
樣品匹配
MATCH 1
DesiredValue [6-13] `value 1`
MATCH 2
DesiredValue [29-36] `value 2`
MATCH 3
DesiredValue [121-128] `value 4`
MATCH 4
DesiredValue [159-166] `value 6`
說明
NODE EXPLANATION
----------------------------------------------------------------------
<div '<div'
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the least amount
possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"] any character except: ''', '"'
----------------------------------------------------------------------
[^\s>]* any character except: whitespace (\n,
\r, \t, \f, and " "), '>' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)*? end of grouping
----------------------------------------------------------------------
\[ '['
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^\]]* any character except: '\]' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
\] ']'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
<div '<div'
----------------------------------------------------------------------
\s? whitespace (\n, \r, \t, \f, and " ")
(optional (matching the most amount
possible))
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"] any character except: ''', '"'
----------------------------------------------------------------------
[^\s>]* any character except: whitespace (\n,
\r, \t, \f, and " "), '>' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
> '>'
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
< '<'
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
div> 'div>'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
\[ '['
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
. any character
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
\[ '['
----------------------------------------------------------------------
( group and capture to \2:
----------------------------------------------------------------------
[^\]]* any character except: '\]' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
) end of \2
----------------------------------------------------------------------
\] ']'
你有沒有考慮使用一個解析器呢? – chris85
它是PHP字符串,而不是Java字符串,你不需要全部轉義。使用x修飾符(如果可以使用nowdoc字符串),而不是使用連接。如果你想處理html(或xml),忘記regex並使用DOMDocument(最終DOMXPath)。 –
其他的事情,關閉方括號不是一個特殊的字符,你不需要逃避它。字符類中的方括號沒有什麼特別之處,你可以寫'[^ []'而不是'[^ \\ []''。 *(你甚至可以寫'[^]]和'[]]',因爲在第一個位置,方括號被看作是一個文字字符。)* –