1
這裏是我的正則表達式:如何在沒有Java 7的正則表達式字符串中匹配大於 uFFFF的Unicode代碼點?
(?x)(?:[A-Za-z:_] | [\\xC0-\\xD6]| [\\xD8-\\xF6] | [\\xF8-\\x{2FF}] | [\\x{370}-\\x{37D}] | [\\x{37F}-\\x{1FFF}] | [\\x{200C}-\\x{200D}] | [\\x{2070}-\\x{218F}] | [\\x{2C00}-\\x{2FEF}] | [\\x{3001}-\\x{D7FF}] | [\\x{F900}-\\x{FDCF}] | [\\x{FDF0}-\\x{FFFD}] | [\\x{10000}-\\x{EFFFF}])
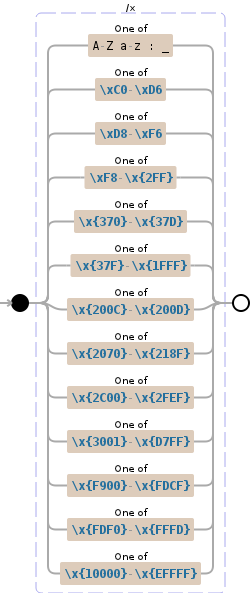
的Java拒絕編譯。它引發了這個例外:
java.util.regex.PatternSyntaxException: Illegal hexadecimal escape sequence near index 68
^/((?:(?x)(?:(?x)(?:[A-Za-z:_] | [\xC0-\xD6]| [\xD8-\xF6] | [\xF8-\x{2FF}]...
^
怎麼了?
爪哇6
看到這個http://stackoverflow.com/questions/3613759/x-escape-in-java –