幾年前,我建立了一個探查器,並在SO上描述了它,以回答我現在找不到的其他問題,介紹如何構建探查器。
它基於我已經使用了幾十年的技術至少部分自動化,其中一個例子是here。它基於堆棧抽樣,關鍵在於信息的呈現方式以及用戶所經歷的思考過程。
關於性能調整的一般信念,在學校教授(由幾乎沒有真實世界軟件曝光的教授教授),並通過50,000名程序員繼續進行 - 這不可能是錯誤的現象,我建議需要質疑並提出更堅定的立場。這種方式讓我感到很孤單,因爲你可能會從圍繞SO巡航中收集信息。
我認爲profiler技術正在逐漸發展(在我看來越好越好)朝着堆棧抽樣和探索結果的方式。下面是我依賴(這你可能會發現一點點不和諧)的見解:
揭開性能的問題,使他們能夠固定,測量性能,是兩個完全不同的任務。它們是手段和目的,不應該混淆。
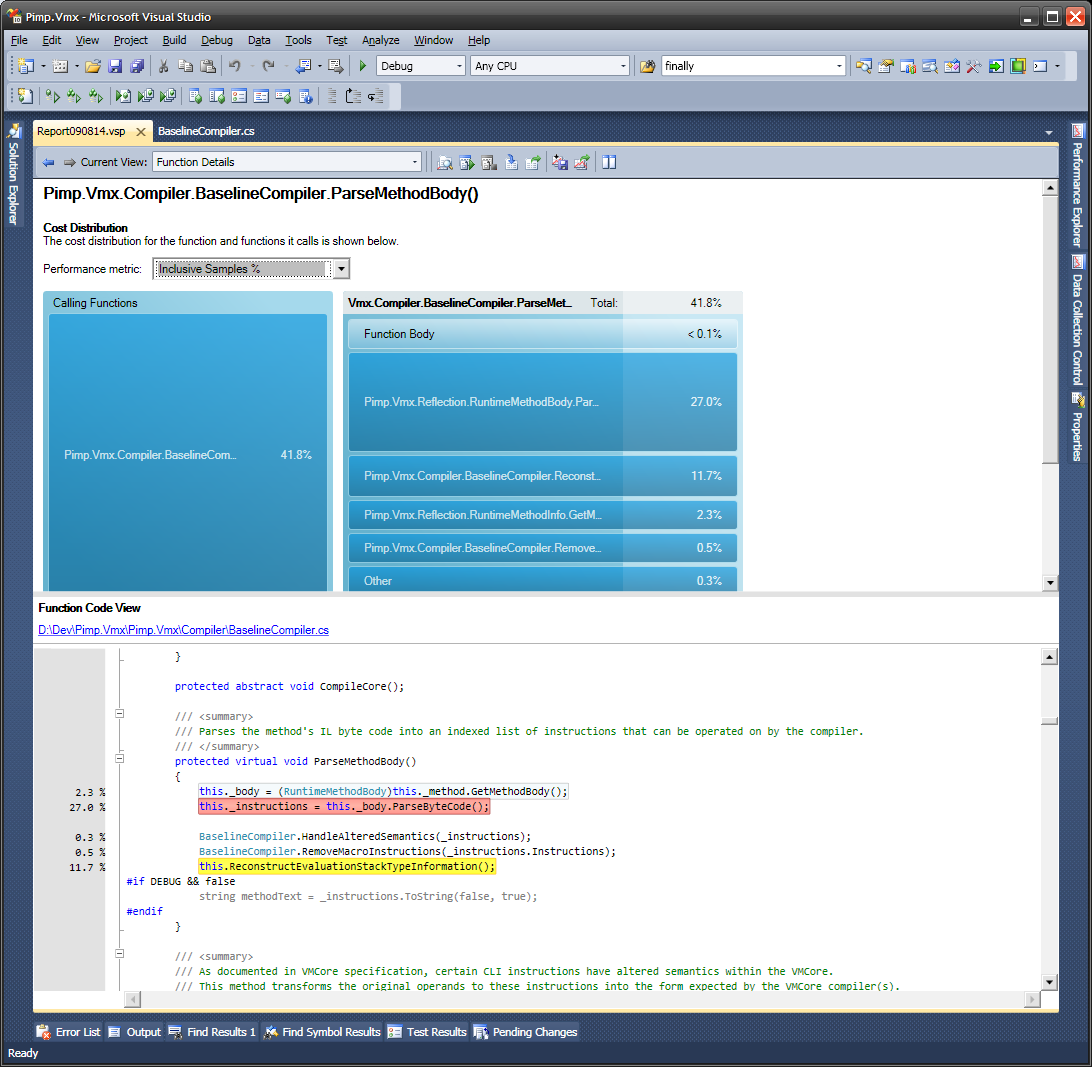
要發現性能問題,我們需要的是找到什麼樣的活動佔了大量的掛鐘時間花在和可以用更快的東西來代替。
這種活動的好處在於,他們需要時間將它們暴露給程序狀態的隨機時間樣本。
如果在您關心的時間間隔內採集樣本,則不需要太多樣本。即在等待用戶輸入的同時進行採樣是毫無意義的。爲此,在我的分析器中,我讓用戶用鍵觸發樣本。
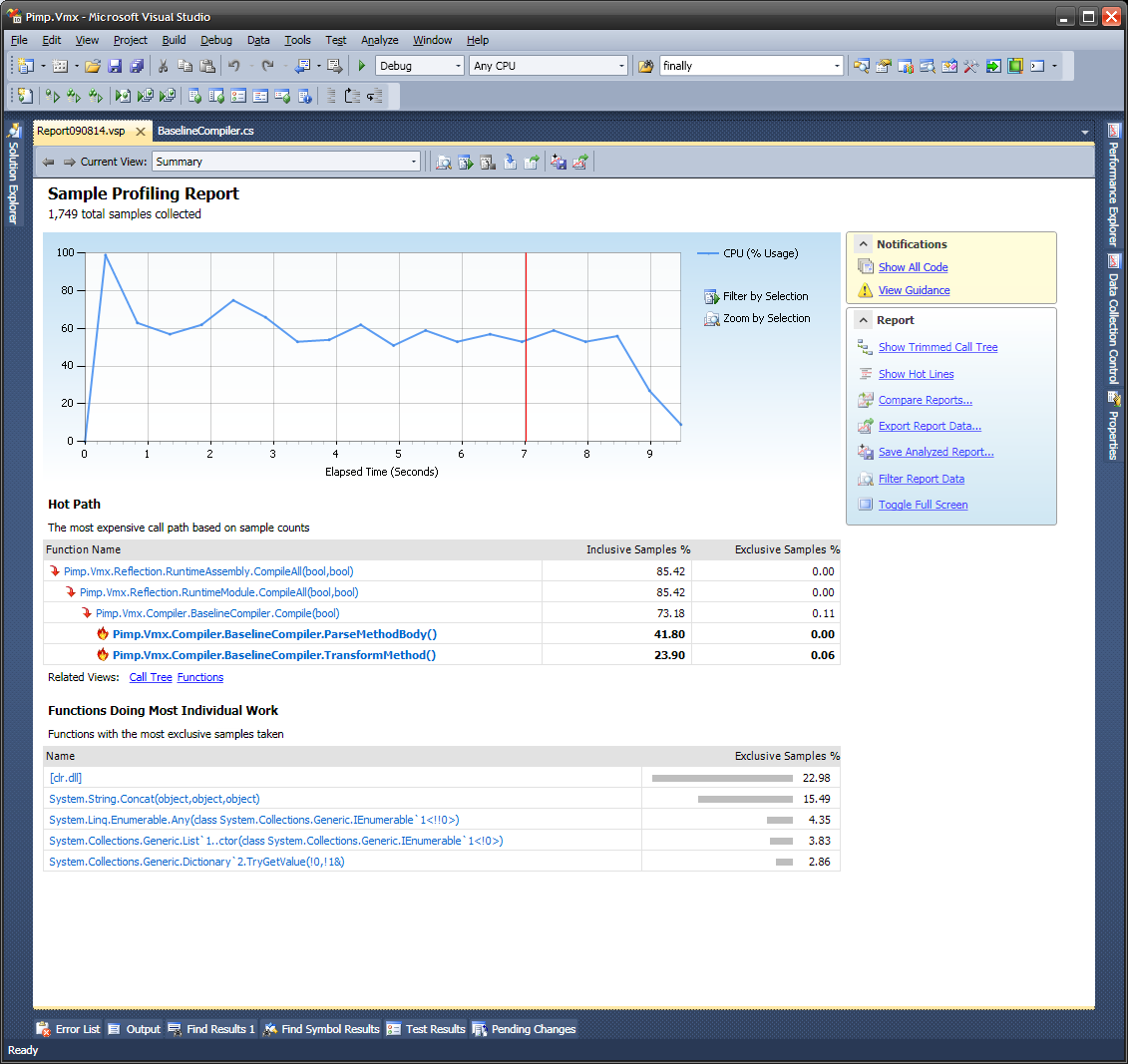
你不需要很多樣品的原因是這樣的。任何給定的性能問題都會花費感興趣區間內壁鐘時間的一小部分X.該區間中的隨機樣本具有「在行爲中捕捉它」的X概率,因此如果採用N個樣本,則在該行爲中捕獲樣本的預期樣本數量爲NX。該樣本數量的標準偏差是sqrt(NX(1-X))。例如,如果N = 20,並且X = 20%,則可以預計大約2到6個樣本顯示問題。這給你一個不準確的問題度量,但它確實告訴你這是值得修復的,它給你一個非常精確的位置,而不需要進一步的偵測工作。
問題通常表現爲更多的函數,過程或方法調用,而不是必要的,特別是隨着軟件變大,具有更多抽象層以及更多堆棧層。我期待的第一件事情是在多個堆棧樣本上出現的呼叫站點(不是函數,但是調用語句或指令)。他們出現的堆棧樣本越多,花費越多。我期待的第二件事是「它們能被替換嗎?」如果他們絕對不能用更快的東西代替,那麼他們就是必要的,我需要去其他地方看看。但通常它們可以被替換,並且我獲得了很好的加速。所以我正在仔細研究特定的堆棧樣本,而不是將它們彙總到測量中。
遞歸不是一個問題,因爲指令的開銷是它在堆棧上的時間百分比的原則是相同的,即使它自己調用它。
這不是我曾經做過的事情,而是在連續的過程中。我修復的每個問題都會使程序花費更少的時間。這意味着其他問題會變得更大一部分時間,使他們更容易找到。這種效應複合化,因此通常可以實現顯着的累積性能改進。
我可以繼續,但我希望你好運,因爲我認爲需要更好的分析工具,而且你有很好的機會。
{kind=link}
{kind=link}
我認爲這是一個有效的問題,尤其是考慮到您正在爲開發人員構建*軟件,並且它是開源的。真的很期待答案! – JoshJordan 2009-08-13 23:04:31
借調。這是一個程序員工具。 – 2009-08-13 23:14:31
我真的很喜歡它是開放源代碼的事實,我將看到如何使用dotTrace進行堆疊。 – 2009-08-19 17:45:25