我有一個基於GGPLOT2,熱圖呈現的某些因素的出現計數。但是,不同的數據集有時並不存在某些因素的實例,這意味着它們各自的熱圖看起來會有所不同。爲了使並排比較更容易,我想添加缺少的級別。不幸的是我沒有成功。添加缺少的因子水平的GGPLOT2熱圖
所以,我有一個看起來像這樣的數據:
> head(numRules)
Job Generation NumRules
1 0 0 2
2 0 1 1
3 0 2 1
4 0 3 1
5 0 4 1
6 0 5 1
> levels(factor(numRules$NumRules))
[1] "1" "2" "3"
我使用下面的代碼來渲染一個很好的熱圖計數每生成規則對所有崗位數量:
ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=factor(NumRules))) +
stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") +
ylab('Number of Rules')
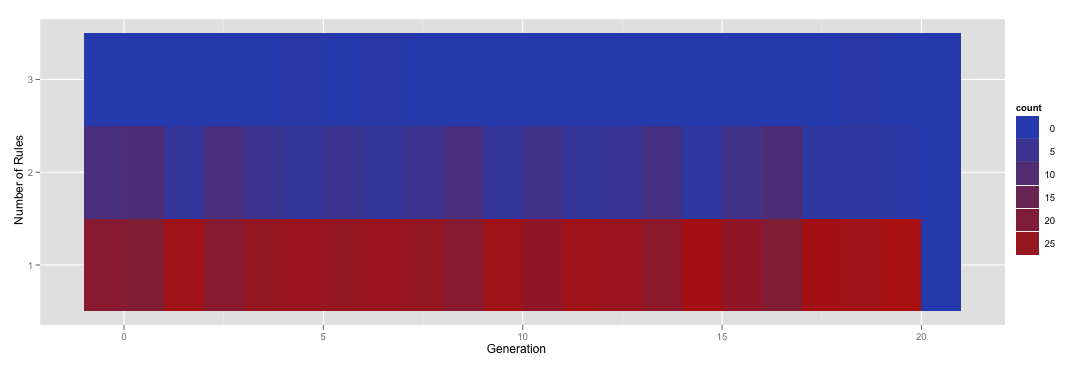
Heat map of count of number of rules by generation for all jobs
因此,熱圖說大多數時候運行只對特定的一代有一個單一的規則,但有時你會得到兩個,並在極少數情況下你會得到三個離子。
現在完全不同的集運行的可能實際上有一個給定的一代零條規則。但是,進行並排比較會有點令人困惑,因爲一張熱圖的y軸在[1,3]中有多個規則,而另一個可能在[0,2]中。我想要做的是標準化熱點圖表,以便他們所有都具有(0,1,2,3)中的因子級別,而不管規則的數量如何。例如,我想重新渲染上面的熱圖,即使在該特定數據框中沒有該圖的實例,也包括一個零規則的行。
我已經與包括設置休息和規模以及諸如此類的東西都沒有用各種咒語[R毆打這一點。我的直覺是有一個簡單的解決方案,但我無法找到它。
更新:
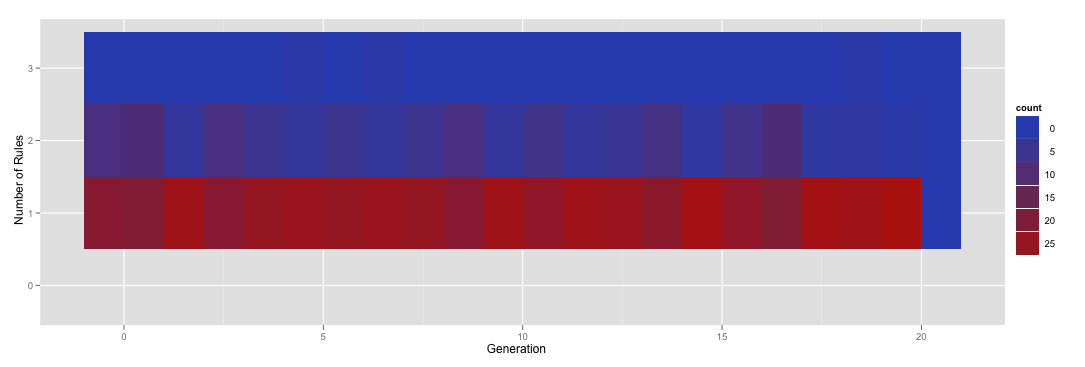
如果我手動指定呼叫的水平factor我得到增加了對零個規則中的一行:
ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=factor(NumRules,levels=c("0","1","2","3")))) + stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") + ylab('Number of Rules')
其中產量this。
不幸的是,你可以看到這個新行不正確着色。到達那裏!


{kind=link}
{kind=link}
謝謝!這就是訣竅! – 2013-03-22 21:47:41