我把我的投票放在使用未綁定的表單來收集必填字段並顯示可能的重複的一面。這裏有一個例子從最近的應用程序:
http://dfenton.com/DFA/examples/Dialogs/LHAAddCustomer.png
(我出去編輯真正的人的名字,並把在假的東西,和我的圖形程序的抗鋸齒是不同的ClearType的,因此古怪)
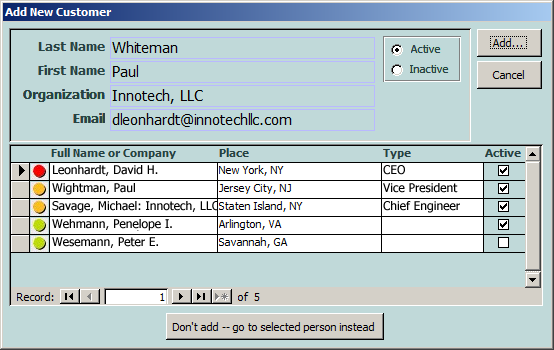
這裏的想法是,用戶將數據放入四個字段中的任何一個(不要求全部),然後單擊ADD按鈕。第一次,它填充可能的匹配。然後,用戶必須決定其中一個匹配項是否爲預期的人,然後再次單擊ADD(即使它是重複的也要添加它),或者單擊底部的按鈕以轉到選定的客戶。
彩色指標旨在傳達比賽的距離。在這種情況下,輸入的電子郵件地址與列出的第一個人完全匹配,並且電子郵件本身的完全匹配被視爲完全匹配。此外,在這個特定的應用程序中,客戶希望儘量減少在同一家公司輸入多個人(這是他們業務的性質),因此組織中的精確匹配被視爲部分匹配。
除此之外,還有使用Soundex,Soundex2和Simil的匹配,以及與Soundex/Soundex2/Simil結合的子字符串和子字符串。在這種情況下,第二個條目是重複的,但Soundex和Soundex2不能捕捉它,而Simil返回67%的相似度,並且我已將敏感度設置爲大於50%,因此「Wightman」顯示爲近似與「懷特曼」相匹配。最後一個。我不知道爲什麼最後兩個在列表中,但顯然有一些原因(可能是Simil和縮寫)。
我通過評分例程運行名稱,公司和電子郵件,然後使用組合計算最終得分。我將Soundex和Soundex2值存儲在每個人的記錄中。當然,Simil必須實時計算,但因爲Jet/ACE查詢優化器知道限制其他字段,因此調用Simil來減少大量數據集(這實際上是第一個應用程序我已經使用了Simil,迄今爲止它工作得很好)。
加載可能的匹配需要一點暫停,但速度並不是特別慢(這個版本取自的應用程序有大約8K個正在測試的現有記錄)。我爲一個在人員表中有25萬條記錄的應用程序創建了這個設計,並且在後端仍然是Jet時它工作得很好,並且在幾年前後端升級到SQL Server後仍然工作得很好。
{kind=link}
如果你喜歡 – 2009-10-07 15:47:23
,你可以捕獲錯誤(忘記實際錯誤號)並顯示自定義消息如果你使用這種技術,你將需要在組成用戶的所有列上創建一個多列索引名稱。這種方法的問題在於它是絕對的 - 永遠不會有兩個同名的用戶。在給出的例子中,這是不可取的。 – 2009-10-07 15:54:16
你是正確的,它會「消耗」一個自動編號。 – 2009-10-07 20:33:40