ArrayList由數組支持。通常,通過索引來尋址某個事物被假定爲O(1),即在恆定時間內。在彙編中,您可以在固定的時間內將內存位置索引,因爲除了基址外,還有一些指令採用可選的索引。數組通常在內存中分配在一個連續的塊中。例如,假設您的基地址爲0x1000(陣列開始),並且您提供的索引爲0x08。這意味着對於從0x1000開始的數組,您想要訪問位置爲0x1008的元素。處理器只需要添加基地址和索引,並在內存中查找該位置*。這可能會持續不斷。所以,假設你有在Java中的以下內容:
int a = myArray[9];
在內部,JVM就會知道myArray地址。就像我們的例子一樣,讓我們假設它在位置0x1000。然後它知道它需要找到9 th下標。所以基本上它需要找到的位置很簡單:
0x1000 + 0x09
這給了我們:
0x1009
使機器可以簡單地從那裏加載它。
在C中,這實際上更明顯。如果你有一個數組,你可以像訪問Java一樣訪問i的位置myArray[i]。但是你也可以通過指針運算來訪問它(一個指針包含指針指向的實際值的地址)!因此,如果您有指針*ptrMyArray,則可以通過執行*(ptrMyArray + i)來訪問i下標,這與我所描述的完全相同:base address plus subscript!
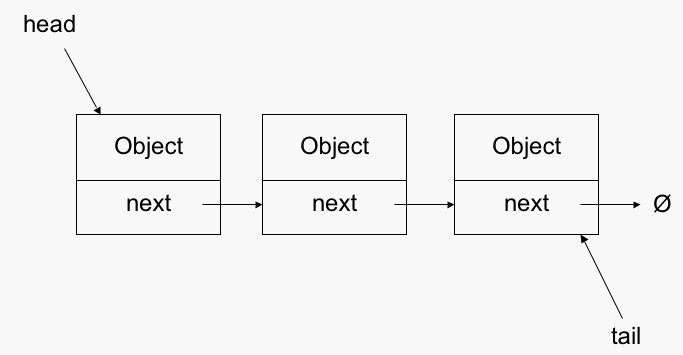
相比之下,訪問LinkedList中的位置的最壞情況是O(n)。如果您回想起您的數據結構,鏈接列表通常有一個head和一個tail指針,並且每個節點都有一個指向下一個節點的next指針。所以要找到一個節點,你必須從head開始,然後依次檢查每個節點,直到你找到正確的節點。你不能簡單地索引到一個位置,因爲不能保證鏈表的節點在內存中彼此相鄰;他們可能在任何地方。
*索引還必須考慮元素的大小,因爲您必須考慮每個元素佔用了多少空間。我提供的基本示例假定每個元素只佔用一個字節。但是如果你有更大的元素,公式基本上是BASE_ADDRESS + (ELEMENT_SIZE_IN_BYTES * INDEX)。在我們的例子中,我們假設大小爲1字節,公式簡化爲BASE_ADDRESS + INDEX。

'arr [7] ='foo';'。那裏。基於索引的訪問。 –
ArrayList由Array支持,並且JVM優化了數組訪問。相反,鏈接列表沒有支持它的數組。 –
按照這個http://stackoverflow.com/questions/716597/array-or-list-in-java-which-is-faster –