1
我想使用正則表達式模塊編寫一小段代碼,該模塊將從.csv文件中刪除一部分url並將選定的塊返回爲輸出。如果該部分以.com/go /結尾,我希望它在「去」之後返回內容。下面的代碼:簡單的Python正則表達式問題
import csv
import re
with open('rtdata.csv', 'rb') as fhand:
reader = csv.reader(fhand)
for row in reader:
url=row[6].strip()
section=re.findall("^http://www.xxxxxxxxx.com/(.*/)", url)
if section==re.findall("^go.*", url):
section=re.findall("^http://www.xxxxxxxxx.com/go/(.*/)", url)
print url
print section
和下面是一些示例輸入 - 輸出:
- 實施例1
- 輸入:
http://www.xxxxxxxxx.com/go/news/videos/ - 輸出:
news/videos
- 輸入:
- 實施例2
- 輸入:
http://www.xxxxxxxxx.com/new-cars/ - 輸出:
new-cars
- 輸入:
我缺少什麼嗎?
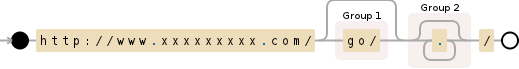
什麼是輸入? –
具有各種列的csv文件。我想讀取的列位於字符串python的位置[6]中。 – Mike
我不太流利的Python,但它好像是「if section == re.findall(」^ go。*「,url ):「行實際上是匹配原始網址,而不是在上一行找到的子網段。 – jwatkins