1
我正在嘗試對版本歷史進行關聯挖掘。我有我的交易數據在MySQL中。 Weka apriori算法需要特定格式的arff或csv文件。它必須有每個項目的列。對於交易中的每個項目,這些值將被指定爲TRUE或FALSE。我正在尋找一種使用Weka InstanceQuery創建這個文件的方法。如果交易數據很大,還有什麼選擇。爲Weka Apriori輸入arff文件
我正在嘗試對版本歷史進行關聯挖掘。我有我的交易數據在MySQL中。 Weka apriori算法需要特定格式的arff或csv文件。它必須有每個項目的列。對於交易中的每個項目,這些值將被指定爲TRUE或FALSE。我正在尋找一種使用Weka InstanceQuery創建這個文件的方法。如果交易數據很大,還有什麼選擇。爲Weka Apriori輸入arff文件
我可以回答第二部分:選項如果交易數據很大。 Weka是一個很好的軟件,但他們的apriori實現速度非常慢。我推薦使用http://fimi.ua.ac.be/src/(我使用Ferenc Bodon列表中的第一個)。
Bodon的實現中使用特里數據結構,而不是Weka的使用哈希表。因此,我在我的工作中發現,Weka需要3天的時間才能完成Bodon的實施可能需要不到一個小時的時間(是的,差異是巨大的!)。
此外,Bodon的實現使用一個簡單的輸入格式:1行每筆交易,由空格分隔的項目。
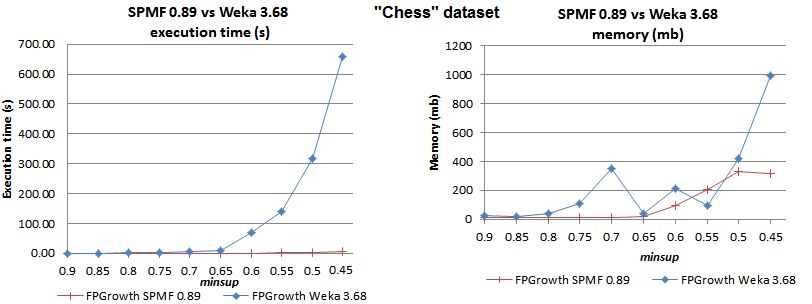
如果你想快速的Java實現FPGrowth或先驗的,看看我的項目SPMF。 SPMF中的FPGrowth實現在某些數據集上比Weka實現多達兩個數量級。例如,你可以看到這樣的性能比較:
http://www.philippe-fournier-viger.com/spmf/performance/chess_fpgrowth_spmf_vs_weka.png
這是主要的項目網頁:
http://www.philippe-fournier-viger.com/spmf/index.php
而且,請注意,SPMF提供了集挖掘50餘種算法,關聯規則挖掘,順序模式挖掘等。另外,SPMF的GUI版本也支持Weka使用的ARFF格式。
{kind=link}
是的我試過Weka Apriori以及Weka FP Growth。對於具有大約120個屬性和僅8個事務的數據,它會導致堆錯誤。增加堆的大小並沒有太大的幫助,因爲在現實世界中,我的輸入擁有更多的數據。我在看R,有沒有人先嚐試R?我需要從java中調用它。我見過Rcaller這樣做。如果任何人都可以評論R apriori的表現以及它可以處理的投入交易的數量,那將會很有幫助。 – user1239080
Weka的行爲並不感到驚訝!不知道R中的apriori;但如果您的目標是從Java調用,則可以考慮通過Runtime.exec()調用C++可執行文件。 – mvarshney