3
我有幾個關於如何神經網絡的BP算法代碼的問題:反向傳播問題
拓撲我的網絡是輸入層,隱含層和輸出層。隱藏層和輸出層都具有S形功能。
- 首先,我應該使用的偏見? 要在哪裏連接我的網絡中的偏見 ?我應該在隱藏的 圖層和輸出圖層中每層放置一個偏差 ?怎麼樣 輸入層?
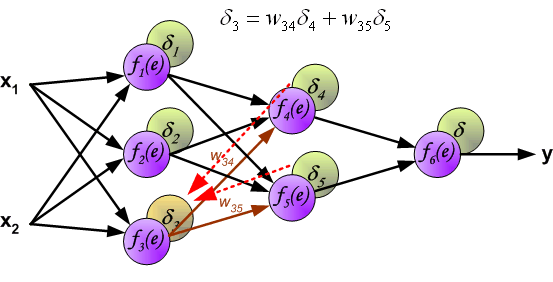
- 在這種link,它們限定的最後增量作爲輸入 - 輸出和它們backpropagate三角洲如可在圖中看到的。他們擁有一張表,在實際上 以前饋方式傳播錯誤之前,將所有增量加上 。這是一個 偏離標準 反向傳播算法? alt text http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop_files/img13.gif
- 我應該隨時間而減少的學習 因素?
- 萬一有人知道,是有彈性的 傳播在線或批處理 學習技術?
{kind=link}
感謝
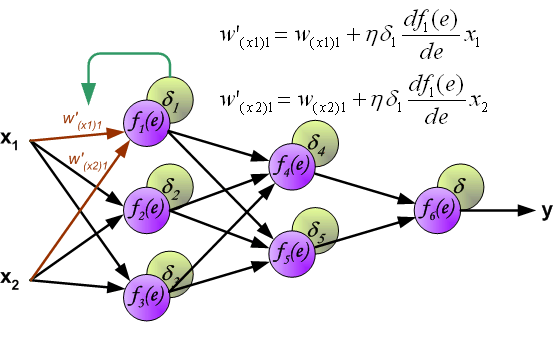
編輯:一兩件事。在下面的圖片中,假設我使用sigmoid函數,d f1(e)/ de是f1(e)* [1- f1(e)],對吧? alt text http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop_files/img14.gif
{kind=link}
我的目標是泛化。我現在正在使用tanh。除了那些,你會有什麼建議? – 2009-12-13 20:06:25
隱式和輸出神經元的tanh和線性函數分別適用於連續函數映射。階梯函數對於模式識別非常有用。請在您的問題中添加更多詳細信息。 – Zaid 2009-12-14 06:25:12