5
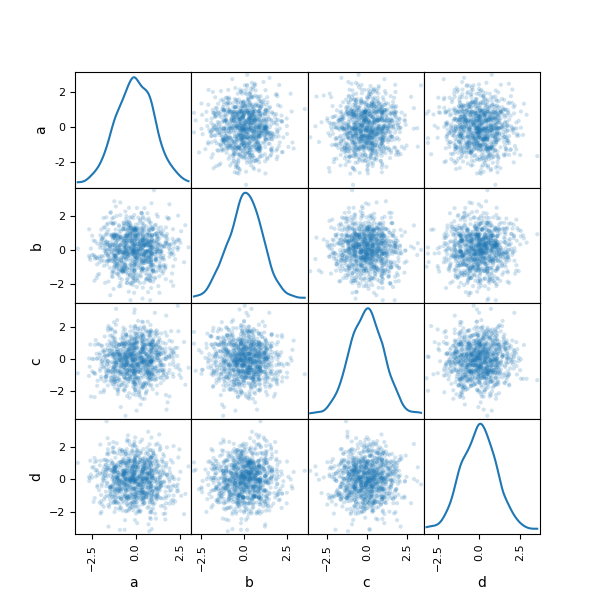
我正在用Pandas繪製一個散點圖矩陣,但第一個繪圖的刻度標籤有時會被正確繪製,有時會被錯誤地繪製。我無法弄清楚什麼是錯的!散點圖中的刻度線標籤與熊貓的繪製不正確
下面是一個例子:

代碼:
from pandas.tools.plotting import scatter_matrix
import pylab
import numpy as np
import pandas as pd
def create_scatterplot_matix(X, name):
"""
Outputs a scatterplot matrix for a design matrix.
Parameters:
-----------
X:a design matrix where each column is a feature and each row is an observation.
name: the name of the plot.
"""
pylab.figure()
df = pd.DataFrame(X)
axs = scatter_matrix(df, alpha=0.2, diagonal='kde')
for ax in axs[:,0]: # the left boundary
ax.grid('off', axis='both')
ax.set_yticks([0, .5])
for ax in axs[-1,:]: # the lower boundary
ax.grid('off', axis='both')
ax.set_xticks([0, .5])
pylab.savefig(name + ".png")
傢伙,任何人!
編輯(X的例子):
X = np.random.randn(1000000, 10)


{kind=link}
你有一個設計矩陣'X'的例子嗎?例如,可以使用一組隨機值輕鬆創建一個。這樣可以更容易在本地嘗試。 – Evert 2014-10-07 15:31:16
@Evert請參閱編輯。 – 2014-10-13 15:45:40