-1
import re
caps = "bottle caps/ soda caps/ pop caps"
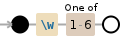
regex = re.findall(r"\w[1-6]", caps)
print(regex)
輸出爲:在常規困惑表情的Python
[]
如果我這樣做
import re
caps = "bottle caps/ soda caps/ pop caps"
regex = re.findall(r"\w[1-6]*", caps)
輸出繼電器是:
['b', 'o', 't', 't', 'l', 'e', 'c', 'a', 'p', 's', 's', 'o', 'd', 'a', 'c', 'a', 'p', 's', 'p', 'o', 'p', 'c', 'a', 'p', 's']
我怎麼使它輸出:
["bottle caps", "soda caps, "pop caps"]
我知道你們會推薦使用.split,但我想了解的正則表達式更
我已經試過這還有:
import re
caps = "bottle caps/ soda caps/ pop caps"
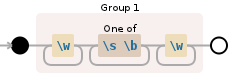
regex = re.findall(r"\w[1-6]?\s*\w[1-3]*", caps)
print(regex)
輸出:
['bo', 'tt', 'le', 'ca', 'ps', 'so', 'da', 'ca', 'ps', 'po', 'p c', 'ap']
什麼發生了什麼?

@ nu11p01n73R _I知道你們會建議使用.split,但我想了解正則表達式more_ – hjpotter92
're.findall(R'\ w +帽','帽') - >'['瓶蓋','蘇打帽','流行帽']' – wim